Recurrent neural networks (RNN) are a type of deep learning algorithm.
They are frequently used in industry for different applications such as real time natural language processing.
RNNs are also found in programs that require real-time predictions, such as stock market predictors.
The RNN can make and update predictions, as expected. However, the system, unlike CNNs and ANNs, can also incorporate memory from previous tests.
This ability to use the memory of past actions makes and RNN powerful for making predictions in real time for ongoing activities.

Reinforcement Machine Learning
Recurrent neural networks are similar in some ways to simple reinforcement learning in machine learning.
If you want to learn more about these algorithms before diving into more complex RNNs, you can check out this article.
There is some mathematical intuition to understand before we start to implement these algorithms using python. This will help you to know how the networks are created so that you can use them effectively.
This article on recurrent neural networks will cover the intuition first before moving into implementation.
What is an RNN?
As we discussed above, a recurrent neural network is a neural network with memory. It uses this memory to incorporate knowledge gained from previous experiences into the predictions.
For example, imagine you are using the recurrent neural network as part of a predictive text application, and you have previously identified the letters ‘Hel.’ The network can use knowledge of these previous letters to make the next letter prediction.
The algorithm can predict with reasonable confidence that the next letter will be ‘l.’ Without previous knowledge, this prediction would have been much more difficult.
How does a Recurrent Neural Network work?
Below is a diagram showing the intuition behind an RNN. You will note that there are two images, rolled up and rolled out.
As you can see you use the inputs and data from the previous test to make a prediction. This data is known as the context unit.
The context unit data and error of the prediction is then fed back into the system to help make the next prediction.
Each prediction is made at a different time step.
When you roll out the RNN, this is easier to see.
Make sense? This all looks pretty simple, doesn’t it?

The RNN is taking the knowledge gained from the previous prediction and passing this onto the next calculation.
However, there is an issue, vanishing gradients.
What on earth is a ‘vanishing gradient’ I hear you say!
Keep reading, and all will become clear – plus I’ll teach you how to get around this issue.
Understanding the intuition behind vanishing gradients
As if the road to implementation of deep learning algorithms wasn’t complicated enough, now we have to worry about things that vanish (and explode)!
The problem of vanishing gradients occurs while the neural network is looking to learn from previous instances (the information gained by looking back in the timesteps).
The reason this is an issue is that you are starting with a small update number.
When you update neural networks, you do so by updating weightings. Weightings are typically very small when you start training the network.
This causes problems when back-propagating through the time steps.
How to visualise vanishing gradients
To help you visualise the mathematics here, imagine you are looking back at something in the distance.
You and the something used to be in the same place, but now you have moved forward.
Now imagine that the thing you are looking at is an ant.
When you stood next to the ant, you could see it. However, now you have moved forward you can no longer see it, it has become insignificant.
The problem of vanishing gradients isn’t just that the small update becomes insignificant as you move back through the timesteps.
The second problem this causes is that the now insignificant value is what is used to update all the time steps moving forward in the neural network predictions with prior knowledge.
Essentially you end up trying to update with insignificant values. You are not learning.
Conversely, if you start updating with a value that is too large initially, the mathematics means that this value grows and grows as you go back in time.
In this scenario, you end up with exploding gradients. Also bad.
The Mathematics of Vanishing Gradients
I’m not going to go into too much detail on the mathematics behind vanishing gradients as it is complicated and you don’t really need to know it – Thank you free libraries!
However, if you feel like you have to see it before you continue, try this blog.
How to Combat Vanishing (and Exploding) Gradients
You will be pleased to know that some very talented mathematicians were able to resolve the issue of vanishing gradients.
This research allowed recurrent neural networks as we now know them to become useful.
The solution they identified is known as LSTMs (Long Short-Term Memory Units).
What are LSTMs (Long Short-Term Memory Units)?
The way that these Long Short-Term Memory Units work is by maintaining a constant value of the error as it is back propagated through the system. This means that instead of the gradient getting smaller (or larger) as it moves back through the system, it remains the same.
When you look at the name, long short-term memory, it kind of makes sense. You are remembering the short term error, over a long time (multiple backward timesteps).
Aside from this difference, the rest of the system is pretty much the same.
Check out the below diagram to see how it works.
There are different valves marked by the X, that determine whether or not it gets updated.
For a detailed explanation try this article.
We have now covered all of the intuition that you need to be able to understand your recurrent neural network.
That wasn’t too challenging now, was it?
Good news, we are now heading into how to set up these networks using python and keras.
Enjoy!
Step by Step guide into setting up an LSTM RNN in python
Now we are going to go step by step through the process of creating a recurrent neural network.
We will use python code and the keras library to create this deep learning model. The process is split out into 5 steps.
Don’t panic, you got this!
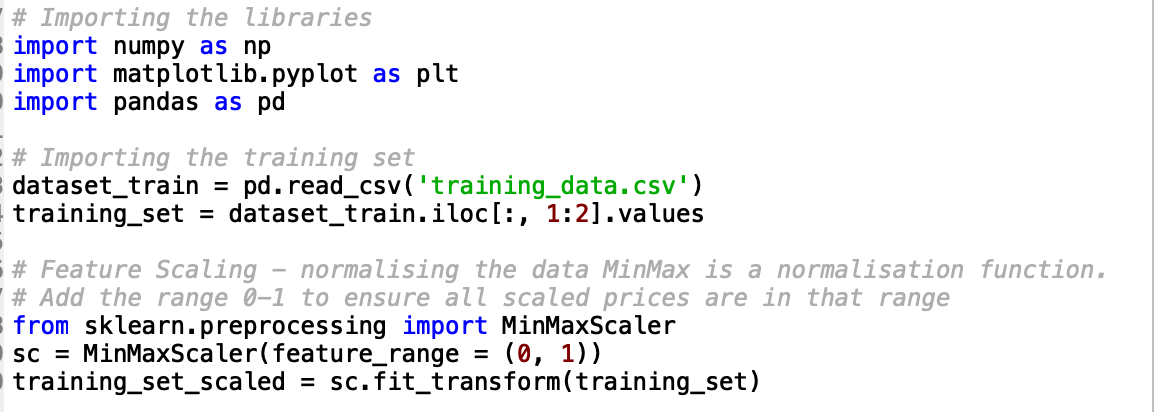
Step 1: Data cleanup and pre-processing
As always the first step in creating your model is cleaning your data and preprocessing it ready to go into the model.
I cannot say enough just how important this is if you want a useful prediction.
Are you using your RNN to do natural language processing? You can get more information on how to pre-process your text-based data set in this article.
There are additional steps for preprocessing text, so if this is your goal definitely check out this article.
Step 2: Getting your data into the right structure to include timesteps
The unique thing about recurrent neural networks is looking back through the different time steps.
This is a new step for us in our deep learning journey.
If you think about the diagram we shared earlier on the structure of the calculations in the RNN, you will note that there are 3 inputs within your training data.
- Your vector of input data
- The number of timesteps
- The number of indicators you are looking at
To get your data into the correct form to be understood by the RNN you need to update the input format using the below code.

In this example, we are using 60 timesteps, but you can update it to include more or less depending on the performance of the RNN.
One of the more complex parts, in my opinion at least, is getting your data into the correct shape to be processed by the LSTM.
The shape you are looking for is:
(number of rows, number of columns, number of features)
Where:
- Number of rows = tuple of samples
- Number of columns = tuple of time steps
- Number of features = input features
This article on machine learning mastery covers this part of the process really well.
When it comes to shaping your data for multiple features you need to modify the input data so that you are creating a matrix of 2 features to start.
The first step is to create an array with the data for both your features.
You then reshape it using the same process as with one feature to essentially rotate it on its axis.
Finally, you update the final input number to 2.
Another way you can create timesteps if you are using Keras for your model is through the TimeSeriesGenerator class. Again there is a great article on ML Mastery on how to do this if you need help.
Step 3: Setting up, compiling and fitting your Recurrent Neural Network
You will be pleased to know the process here is very similar to setting up ANNs.
The process is as follows:
- Initialize
- Create your input and hidden layers
- Create the output layer
- Compile your RNN
- Fit your RNN to the test set
Here’s the code:
Step 4: Making your predictions
Again this is very similar to previously covered tutorials.
You will be comparing your training data and predictions from the RNN to the test data.

Step 5: Visualising your data
Now that everything is set up, it’s time to look at your data. You are wanting to compare the training and test set.
As the saying goes, a picture speaks 1000 words, so we want to use a graph.
In this case, we will use a line chart.
The example below here is from an RNN run for stock price predictions.

Ready to get started with Machine Learning Algorithms? Try the FREE Bootcamp
Other examples using RNNs and Visualisation
If you are interested to see some more exciting visualisations of RNN output predictions and natural language processing, then check out this article.
It also covers a lot of additional background information that will help improve your understanding.
The image below is taken from that article and shows the different letter predictions made by the RNN. The darker the colour, the more probable the predictions.
And that’s it, you’ve officially created a recurrent neural network!
That deserves a celebration!
How to improve your recurrent neural network
Not happy with how you RNN is performing? Don’t worry, there are some options to help you improve it.
How to refine your RNN
There are a couple of simple steps you can take to help improve the performance of your recurrent neural networks:
- More layers – Adding more layers can help get a more in-depth analysis
- Try different numbers of timesteps and error calculations/kernels
- Additional inputs – adding more indicators can help the system understand the space better
- Taking inspiration from our neural network, let’s look back
In this week’s tutorial, you have learned a lot about the power of recurrent neural networks.
You now understand:
- How an RNN works
- The challenges associated with traditional RNNs a
- How to solve the problem of vanishing and exploding gradients
- Step by step process to create an RNN in python using keras
- Terchniques to refine your neural network to improve predictions
If you are interested in going back to review reinforcement learning theory as a refresher try this article.
Advertising Disclosure: I am an affiliate of Udemy and may be compensated in exchange for clicking on the links posted on this website. I only advertise for course I have found valuable and think will help you too.
If you have found this content helpful, I recommend the course linked below which gave me a baseline understanding of the materials and python code shared here.
Deep Learning A-Z™: Hands-On Artificial Neural Networks
Love it? Pin it!