Reinforcement learning is used in all sorts of applications in artificial intelligence.
From teaching robots to walk through teaching Siri to understand your voice, reinforcement learning is used everywhere.
It’s a vast topic with multiple specializations, but where do you start if you want to get into reinforcement learning in python?
Ready to get started with Machine Learning Algorithms? Try the FREE Bootcamp
Multi-arm bandit reinforcement learning is a great place to introduce the concepts you need.
More importantly, reinforcement learning can help you win in gambling and in business.
This reinforcement learning tutorial will show you how.
We’ll get to that but first, let’s introduce the concept of reinforcement learning.
What is reinforcement learning?
In reinforcement learning the system learns from the environment.
When the system does something right, it is rewarded.
When it does something wrong, it is not.
The aim of the game in reinforcement learning is to maximize the reward.
Simple isn’t it?
The system learns in a very similar way to how a person would learn.
Right, let’s get onto the reinforcement learning tutorial and reinforcement learning in python.

What will this reinforcement learning tutorial cover?
In this reinforcement learning tutorial, we will cover machine learning algorithms to target the multi-arm bandit problem. We will then show how to implement reinforcement learning in python.
The multi-arm bandit problem refers to an old gambling problem of which slot machine to use.
The arm refers to the division of the slot machine which you need to pull to see if you’ve won.
The algorithm will learn from the first few ‘pulls’ of the machine and then be able to predict which device will give you the highest reward.
The game aims to maximize the reward and minimize regret.
Regret is where you are not choosing the best option to win.
Primarily, this reinforcement learning tutorial will teach you how to win!

What are the different algorithms for reinforcement learning?
There are many different types of algorithms for reinforcement learning in python.
Two of the most common for the multi-arm bandit problem are upper confidence bound and Thompson sampling.
1/ Upper Confidence bound reinforcement learning tutorial
In Upper Confidence Bound reinforcement learning you assign a confidence level to each of the options for whether you will get a reward or not.
As you test each option, the confidence interval will go up when you get the reward, and down when you don’t.
To maximize your chances of getting the reward you always go for the option with the highest upper confidence boundary. Hence the name!
Eventually, one option will have upper confidence bound so much higher than the others it will always be chosen.
By always choosing the option with the highest upper boundary to maximize your reward.
If you want to learn more about upper confidence bound mathematics, you can read it here.
2/ Thompson Sampling reinforcement learning tutorial
In Thompson Sampling, you choose a random point at which to test your problem.
You then run the test and see the reward you get.

You are trying to determine which option gives you the highest probability of winning.
After testing a few options, you will know which option has the highest probability of winning.
Once you have that information, you can then move forward with just that option. Therefore, maximizing the total reward.
If you want to know more about the mathematical proof behind this algorithm you can see it here.
Which reinforcement learning algorithm should you choose?
For this reinforcement learning tutorial, before we get onto implementation, we will cover how to choose an algorithm.
The easiest way to determine which reinforcement algorithm to use is by testing both and seeing which gives the maximum reward.
But this isn’t always a practical solution.
So I’ll let you in on a secret, as a general rule, Thompson Sampling will give you a greater reward.
The reason for this is that Thompson sampling is a probabilistic method as opposed to a deterministic approach. This means that it is able to learn more quickly.

How do you implement reinforcement learning in python?
Want to know something exciting?
Yes?
Well, you don’t need any modules from Sklearn to implement reinforcement learning in python!
You just need a couple of ‘normal’ python modules, and you’re on your way.
Even better, because your algorithm is learning as it goes with the data, you don’t need to do any data pre-processing!
Win!

Implementing Reinforcement Learning in python
Below are reinforcement learning tutorials on implementing the multi-arm bandit problem.
Before we go into the specifics, you will need to understand one critical concept of python programming.
The concept you need is loops!
You use loops to test each scenario and evaluate whether you get the reward.
If you get the reward, this option becomes the winner.
You then test again, and if you are still rewarded, you stay with it.
- Upper Confidence Bound (link)
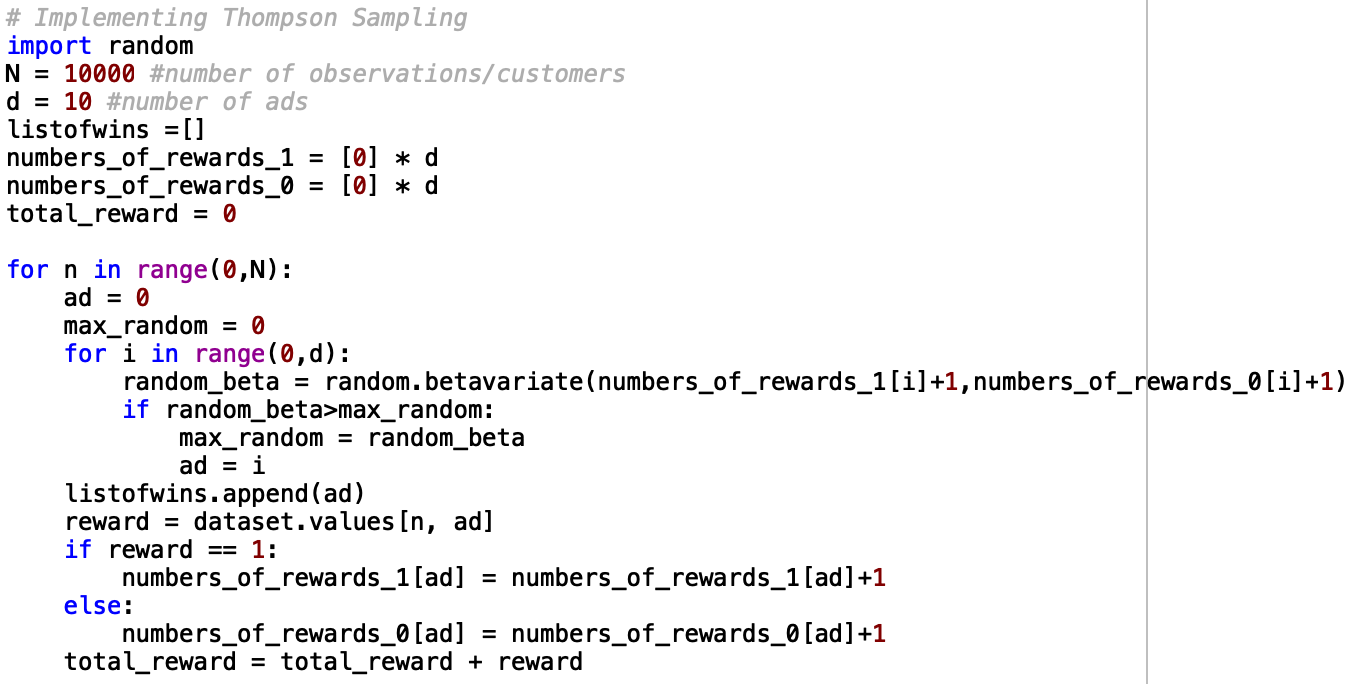
- Thompson Sampling – the below screenshot goes through exactly how to implement Thompson Sampling reinforcement learning in python
Once you have implemented the algorithm, you can then visualize the results using a simple histogram to see which option was the best performing.
Histograms are easy to plot using the matplot module.
If you import:
import matplotlib.pyplot as plt
You can then plot a simple histogram using:
plt.histogram
Just in case you want to customize your plot though, here is the link to the documentation.
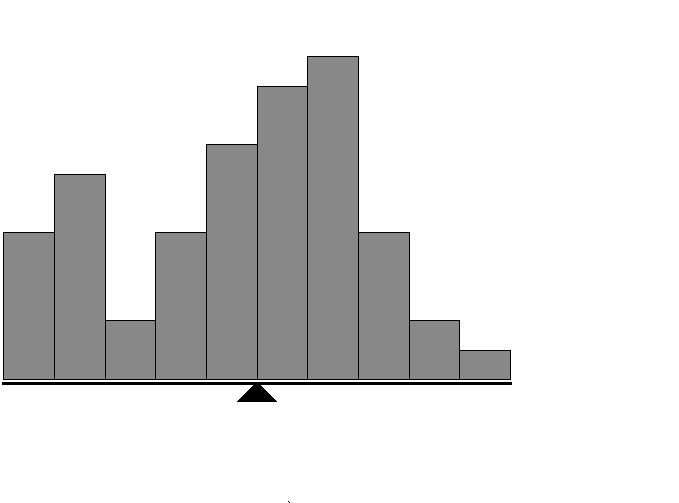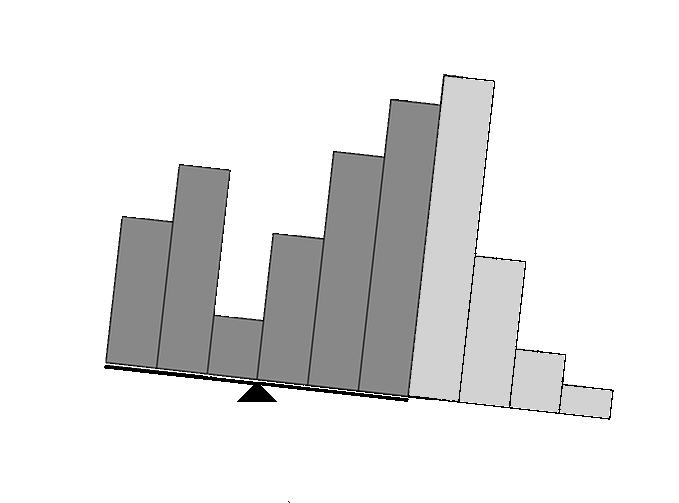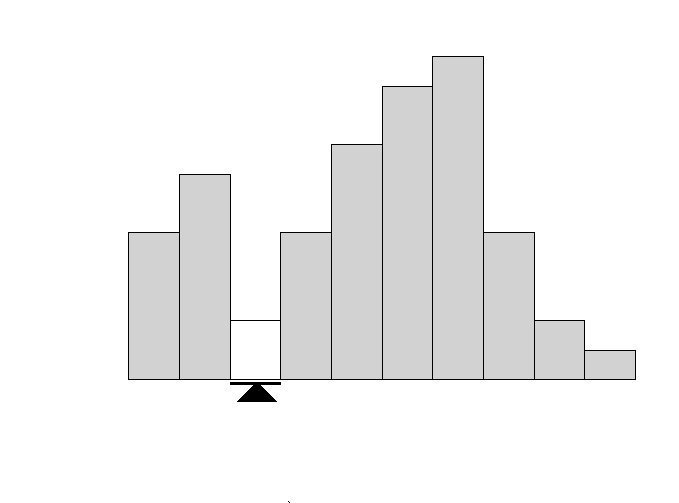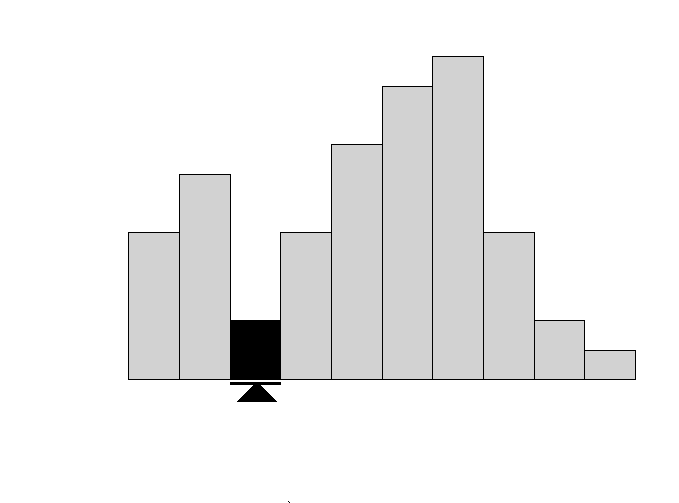
So there you have it, that’s how to implement reinforcement learning in python to solve the multi-arm bandit problem.
And that’s it for this reinforcement learning tutorial!
I hope you enjoy using this algorithm and winning with reinforcement learning!
Advertising Disclosure: I an affiliate of Udemy and may be compensated in exchange for clicking on the links posted on this website. I only advertise for course I have found valuable and think will help you too.
If you have found this content helpful, I recommend the course linked below which gave me a baseline understanding of the materials and python code shared here.
Machine Learning A-Z: Hands-On Python & R In Data Science