One area that people new in the field of machine learning a particular terrified about is hyperparameter tuning.
The feeling is that you need to have a Ph.D. in machine learning in data science to be able to understand these metrics.
Don’t worry; this is not the case.
In fact, by understanding a few key parameters, you can update machine learning algorithms to get state of the art results.
We are going to talk about just five different ways that you can tune the parameters of your machine learning algorithm to help optimize it.
We’re not going to go into very complicated explanations. However, you will gain enough to be able to update and optimize your machine learning projects effectively.
Hyperparameter tuning is a skill that you will be able to pick up. With this skill, you can improve your analysis significantly.
Without any further ado, let’s jump on in.
What are hyperparameters?
There are parameters, and there are hyperparameters. The machine learning algorithm learns parameters – these include the weights and the biases that combine with the input data to form the output prediction.
Hyperparameters, on the other hand, are chosen by the machine learning engineer to help the algorithm to learn and optimize effectively.
There are five hyperparameters you will see today that you can experiment with to help optimize your algorithm.
Once you understand these, you will be ready to work with machine learning algorithms like a pro!
Which are the key metrics in hyperparameter tuning? And why?
To help build up your understanding of hyperparameters, we will start with the most commonly understood and build-up to the more math-heavy ones.
Don’t worry, though; you can understand all of what you will learn today.
Hyperparameter Tuning 1: Leaning rate
The gradient descent algorithm tries taking a step in some direction to determine the way you need to move in to get to the optimum solution. Once this direction has been calculated the weights and biases in the algorithm are updated, and the predictions run again.
As always, you repeat this process until you reach the optimum solution. First, you understand the difference between predicted and actual results, then identify which way you need to go next and update your algorithm. Finally, you find yourself at the optimum solution.
Understanding the Learning Rate for hyperparameter tuning
The learning rate determines how big a step the gradient descent algorithm takes. The bigger the learning rate (step), the quicker you can get to your optimum solution.
At least that’s what you might think, but what if your optimization graph looks like the one below.
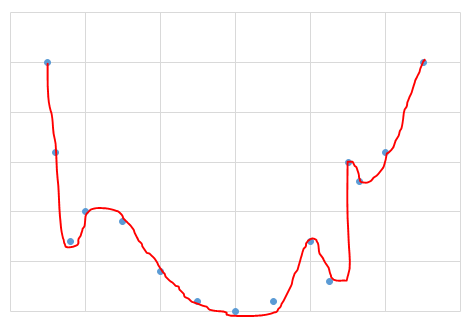
In this scenario, if you take too big a step from the point you are at, you may miss the optimum point completely. Also, if you take too small a step, you could end up stuck at a non-optimal solution or stepping for what seems like forever.
You can optimize the size of the learning rate to balance out speed and the need to find an optimal solution. You can even set up your algorithm to take smaller steps initially. Then move to more significant learning rate steps when it is more confident you close.
Hyperparameter Tuning 2: Number of epochs
The number of epochs is probably the most straightforward parameter to understand.
Whenever you create a machine learning learner, you have to input the number of epochs. The number of epochs is a hyperparameter you can define.
An epoch is one full cycle of running through all of your data and making a prediction.
Usually, an algorithm will require multiple epochs to train correctly. You need to optimize the number of epochs you train your algorithm to balance the risk of underfitting and overfitting.
Too few epochs and you will underfit – meaning your algorithm will make weak predictions on all the data.
Too many epochs and you will overfit. When you overfit, the algorithm is too well optimized for the training data and will make wrong predictions on unseen or test data.
Hyperparameter Tuning 3: Batch size
The batch size is another hyperparameter for you to experiment with.
The batch size determines how many training inputs you test on before updating weights and biases.
The bigger the batch size, the quicker your algorithm will run.
However, there is a potential quality trade-off by keeping the batch size broad.
According to a paper titled, On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima, “it has been observed in practice that when using a larger batch there is a significant degradation in the quality of the model”.
The paper goes on to describe that when using a larger batch size, your algorithm can get stuck and converge in a non-optimal minima.
This non-optimal solution is shown by the poor performance of the algorithm when generalizing.
Have a go at playing around with batch size and see what happens.
Hyperparameter Tuning 4: Weight decay
It’s time to talk about weight decay.
The simple explanation of weight decay is that it temporarily removes the impact of some weights on the predictions. Then for the next run through the data, it adds those weights back in, excluding the effect of different weights.
Weight decay is fantastic for preventing overfitting! This hyperparameter also makes it great for ensuring your networks will generalize better.
There is a cautionary tale in this story, though!
If you add too much weight decay, it will be tough for your algorithm to converge.
As a general rule, most neural networks will perform well with a 0.1 value for weight decay. However, because of the risk that the system will not train, libraries, such as fastai, have their default value set to 0.01.
You can, of course, experiment though. Change up the weight decay and see what happens to the performance of your algorithm.
Ready to get started with Machine Learning Algorithms? Try the FREE Bootcamp
Hyperparameter Tuning 5: Momentum
If it’s going well, keep going!
That is the principle behind momentum.
The momentum, in deep learning, refers to the moving average of the gradients calculated during gradient descent. When you run gradient descent (or stochastic gradient descent) during the network training process, you can combine the results with momentum to help the algorithm to train faster.

Impact on training time:
| momentum | Training time |
| 0 | 217 |
| 0.9 | 95 |
Source: https://www.willamette.edu/~gorr/classes/cs449/momrate.html
Not hyperparameter tuning but still relevant…
…Activation Functions!
Ok, so activation functions aren’t technically hyperparameters. However, you do get to choose the activation function within your neural network, so it is essential to understand how they work.
The activation function determines which of the neurons activate during training for each batch.
When a neuron is activated, it indicates which features the data set does and does not have. Therefore helping the network to make a prediction.
The activation function is applied to the prediction from the run. If the calculation delivers a result over the threshold, the feature is activated.
The most common activation functions are in the below table.
Tools for hyperparameter tuning
I bring you good tidings of great joy!
Though you may enjoy and learn a lot from experimenting with hyperparameter tuning (and I wholeheartedly recommend you do some experiments), you don’t have always to do all the tuning.
Some beautiful people have created automated hyperparameter tuning classes.
In this next section of the article, we will take you through 3 of the most popular automated hyperparameter tuning tools.
The code you will see is taken from a variety of tutorials found online.
You can find examples of how I have used these techniques in real-world projects on my GitHub portfolio. I am continuously adding to this portfolio so expect to see more techniques covered as it builds up.
Tool 1: GridSearch
This tutorial is shared in the sklearn documentation and has been done on the Iris Classification Dataset.
Grid Search looks at a dictionary of parameters that you provide. This could include different kernels, numbers of estimators, cross-validation.
Basically any parameters you want to test for your algorithm.
Then the GridSearch method will go through and test all of the different combinations to find out which gives the best predictions.
Here is an example of the code.
Tool 2: Random Search
Random search is not quite as accurate as Grid Search under normal circumstances however will find good enough results more efficiently.
Here is a link to a full guide on implementing random search.
The code below covers a small section of the implementation where you create a function to search random parameters.
Tool 3: Bayesian
The final tool I will show you is Bayesian Optimisation
Hyperparameter tuning with Bayesian Optimisation looks at how the algorithm has been performing and uses this data to make a prediction of the optimum parameters based on this.
It sounds fairly obvious but involves a lot of complicated mathematics.
You can get a full overview here.
Taking from the tutorial above, below is a code exert on how to implement Bayesian Optimization.
Before using Bayesian Optimization for hyperparameter tuning you will need to instal it. All the instructions to do this and to further optimize the optimizer are given in the tutorial.
To conclude
When it comes to hyperparameter tuning you don’t need to worry about feeling overwhelmed.
In addition to some algorithm-specific parameters you can work with, there are 6 hyperparameters you need to be aware of:
- Learning Rate
- Number of Epochs
- Weight Decay
- Momentum
- Batch Size
- Activation Functions
To optimize hyperparameters effectively you can experiment yourself or get help from different automated hyperparameter tuning tools:
- GridSearch
- Random Search
- Bayesian Optimisation
I hope this tutorial has removed some of the overwhelm from hyperparameter tuning! Good luck and happy experimenting.